 Tweet
Tweet
I'm guessing that this question might be a bit complex since it may affect all indexing so I've included a great deal of info...
I have a variety of PDFs that have been indexed and that cross reference each other. I used MS Word 2007 metadata features to add the documents Title, Description and Keywords to the coverpage then in converting the PDFs that data carried over in the respective metadata for the PDF. While the value of keywords in a PDF are questionable, this has worked well with Google.
My site has about 7500 files (by Zoom Search results) and 65 PDFs. When a person searches for the name of a PDF, it would be helpful if that was at the top of the list. This is my problem. For example:
My link text is: "PPP-B-601(H) - Cleated Plywood Box"
My document name is: "http://www.woodencrates.org/standards/PPP-B-601.pdf"
And my search term is: "PPP-B-601" or "PPP-B-601(H)"
I have no adjustment for URL length.
This term is all over throughout my site and is referenced multiple times in other PDFs but I need the actual document to come up 1st in a search result. Currently this particular one comes up #6 with positions 1 to 5 also being PDFs.
Is there a way that I can weight this so the proper PDF (based on file name) comes up at the top of the search without generally affecting the results of web page searches?
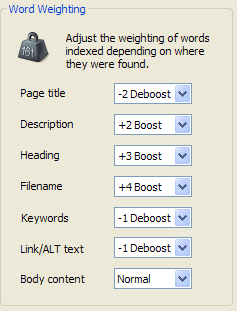
(With my weighting, it may be important to note that all my web pages use the Page Title as the <h1> tag and the meta Description as the <h2> tag.)
Thanks in advance for any help.
I have a variety of PDFs that have been indexed and that cross reference each other. I used MS Word 2007 metadata features to add the documents Title, Description and Keywords to the coverpage then in converting the PDFs that data carried over in the respective metadata for the PDF. While the value of keywords in a PDF are questionable, this has worked well with Google.
My site has about 7500 files (by Zoom Search results) and 65 PDFs. When a person searches for the name of a PDF, it would be helpful if that was at the top of the list. This is my problem. For example:
My link text is: "PPP-B-601(H) - Cleated Plywood Box"
My document name is: "http://www.woodencrates.org/standards/PPP-B-601.pdf"
And my search term is: "PPP-B-601" or "PPP-B-601(H)"
I have no adjustment for URL length.
This term is all over throughout my site and is referenced multiple times in other PDFs but I need the actual document to come up 1st in a search result. Currently this particular one comes up #6 with positions 1 to 5 also being PDFs.
Is there a way that I can weight this so the proper PDF (based on file name) comes up at the top of the search without generally affecting the results of web page searches?
(With my weighting, it may be important to note that all my web pages use the Page Title as the <h1> tag and the meta Description as the <h2> tag.)
Thanks in advance for any help.
Comment